
DeepSeek V4 Finally Drops After a Year of Anticipation

Yesterday marked the end of a long wait for AI enthusiasts who have been watching every development coming out of the Chinese lab. DeepSeek has launched a pre-release version of its V4 model, complete with open weights, for anyone to download and run on their own hardware, representing a significant step forward for the community. The release includes two separate flavors that provide top-tier capabilities without the usual prohibitively high entry barriers.
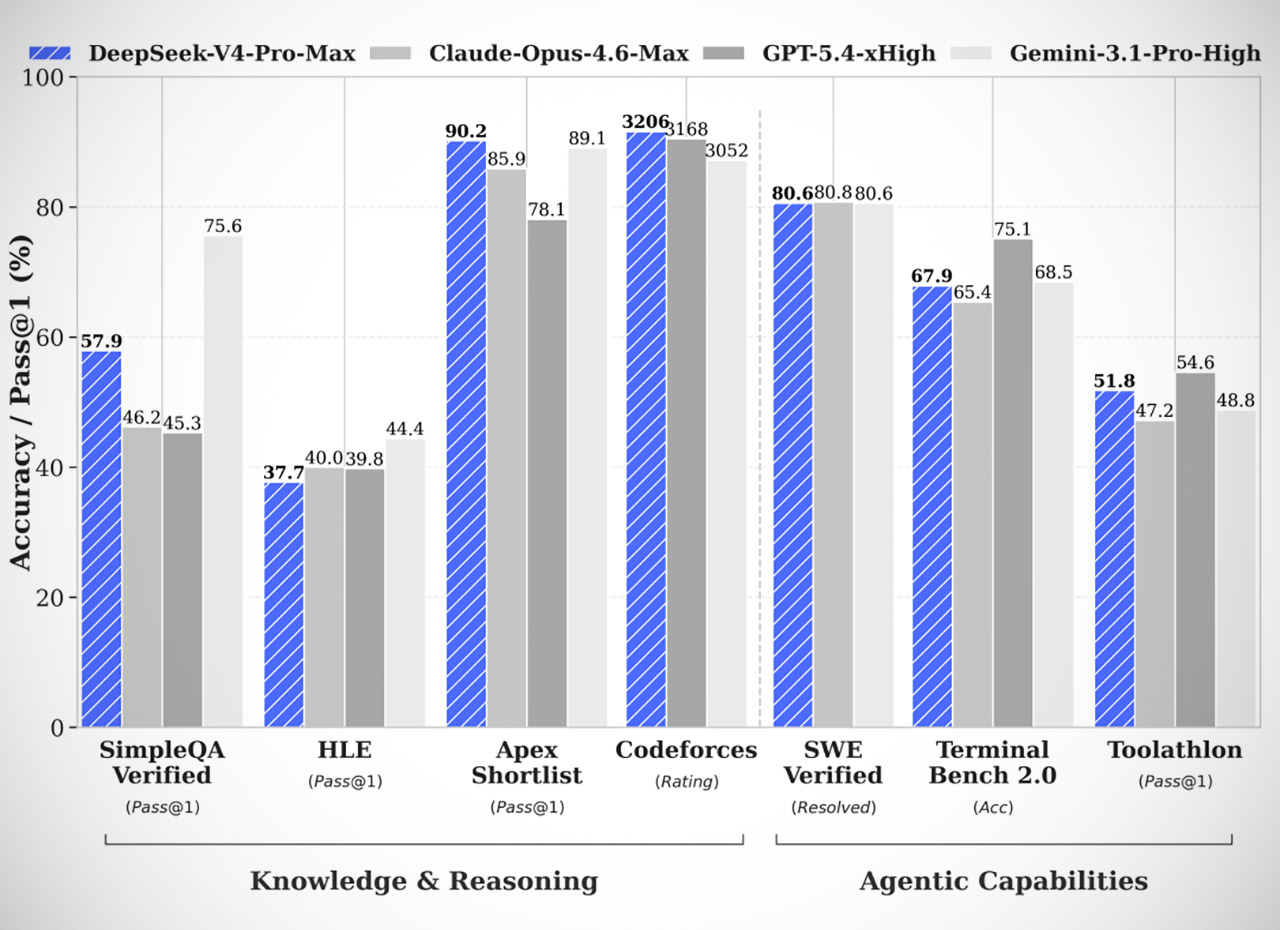
Developers can access the V4 Pro version immediately away using the company’s chat interface and upgraded API. The greater option has 1.6 trillion total parameters, but it only uses 49 billion at a time. This arrangement allows it to match the reasoning strength of the big boys’ top-tier closed models. It outperforms all current open models in math, science, and coding challenges, and it excels at agentic activities as well, handling multi-step occupations like building code projects essentially hands-off. In broad knowledge testing, V4 Pro outperforms all other open models and nearly matches the most recent Google Gemini version.

Plaud Note Pro AI Voice Recorder, Transcribe & Summarize with AI, App Control, Note Taker for Meetings…
- AI-POWERED TRANSCRIPTION & MULTI-DIMENSIONAL SUMMARIES: Plaud Note Pro is your professional voice transcriber, delivering high-accuracy transcription…
- ENHANCED CONTEXT WITH MULTIMODAL INPUT: Capture audio, type notes, add images, and press to highlight key moments for richer context. During…
- CHAT WITH YOUR RECORDINGS USING “ASK Plaud”: Unlock deeper insights with this interactive AI. Ask questions, extract key points, draft emails, and get…
V4 Pro has a smaller brother, V4 Flash, which was released on the same day. This is more aimed toward casual users and uses a total of 284 billion parameters, 13 billion of which are active during operation. Users will see faster reactions while maintaining performance comparable to the Pro version on routine tasks. Both models have the same vast 1 million token context window, which allows them to track enormous quantities of information throughout extended conversations or complex projects without slowing down or breaking the bank.
The reason everything is so efficient is because the model has a new way of looking at tokens. They combined selective compression with a sparse technique, which dramatically reduces memory utilization. The overall product is fairly seamless, whether you converse for a few sentences or feed in a full book’s worth of content without missing a beat. DeepSeek has even made the 1 million context standard across all services, so you don’t have to deal with any additional setup.
Hardware decisions offer another depth to this scenario. They used Huawei Ascend chips for training and optimization. It was partly in response to restrictions on importing certain foreign components. The models function nicely on domestic clusters, and Huawei confirmed full support right up to its most recent supernode systems. It’s a terrific illustration of how Chinese teams are still making progress, even converting possible hurdles into opportunities for local developers.
Anyone can get the open weights from Hugging Face and experiment with their own hardware, or fine-tune the models to meet their specific requirements. The API supports the same old formats, so integrating it with existing tools is simple. Two modes allow you to switch between quick fire reactions and deeper thinking steps, providing you the flexibility you require. Flash is a more affordable alternative, whereas Pro can perform the most difficult jobs requiring full power.
DeepSeek V4 Finally Drops After a Year of Anticipation
#DeepSeek #Finally #Drops #Year #Anticipation







